Should all epidemiologists be data scientists?
The origins of epidemiology as a field can largely be traced back to individuals with medical training (i.e. physicians and nurses) who maintained an interest in the public's health. During the twentieth century we saw a transition from the physician epidemiologist to the research epidemiologist: an individual trained first and foremost in epidemiology and statistics. Indeed, a doctoral degree in epidemiology today is distinct from a medical degree, although a rare breed obtain both degrees. Mervyn Susser has written extensively about the history of the field.
The training as reflected in current epidemiological doctoral programs emphasizes epidemiology, biostatistics, public health, and pathophysiology. In reflecting on the "modern" epidemiologist (I quote as this was penned decades ago), Susser states that a doctoral epidemiologist "is competent in statistics but not a statistician; has a grasp of concrete biomedical reality without being a clinician responsible for the medical care of individuals, and is able to comprehend the basic elements of society and social structure without being a sociologist or anthropologist" (Susser and Stein, Eras in Epidemiology, p173.) I think this is a beautiful assessment, yet it falls short in capturing a core construct of present-day epidemiology: data science.
As I think about the type of work that my colleagues and I engage with, particularly those of us who did our training at similar times (the last decade), I would posit that we spend perhaps half of our time, and possibly more, using data science techniques: data linkage, cleaning, and management; computer programming; etc. In fact, I find it quite difficult to fathom that an epidemiologist could exist today without a set of computer and information science skills. Thus I would amend Susser's definition as follows (mine in italics): "[The modern day epidemiology] is competent in statistics but not a statistician; has a grasp of concrete biomedical reality without being a clinician responsible for the medical care of individuals, is able to comprehend the basic elements of society and social structure without being a sociologist or anthropologist, and can also work with large amounts of electronic data and program complex analytic models without being a computer scientist."
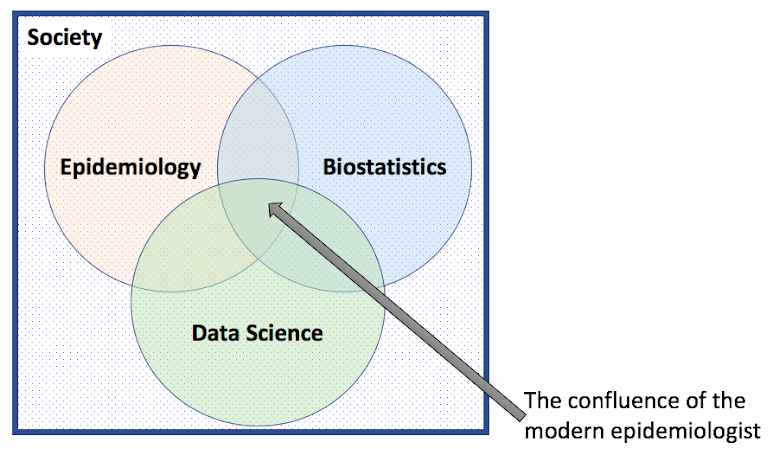
To keep up with the technological revolution in this field, educational programs should focus on the intersection between epidemiology, biostatistics, and computer science: a data science perspective to public health. But what does this actually mean in terms of training for this field? It is true that these skills can be honed through experience without formal training, yet the rigorousness of formal training in data science is nevertheless important. I would advocate that students in epidemiology programs where the curriculum does not include data science components proactively seek out instruction in the following areas: basic to intermediate computer programming, database management systems, health informatics, and data science. Those with these backgrounds will have a greatly improved appreciation and understanding of the data they are working with in epidemiological studies as well as feel comfortable manipulating the data and analytic codes in sophisticated ways, especially those who will use R or Python. All too often I see seasoned epidemiologists (specifically academicians) who are too hands off with data and can no longer program statistical models. There could be many reasons for this including time spent on grants, ensuring junior researchers get the hands-on experience, lack of familiarity with data sources/implementation techniques and so on. While it is important to let others obtain the hands-on experience, it is equally important to know the methods by which this is accomplished.
As an example, suppose we are interested in studying the effects of the community deprivation and hospitalization. We contend that those living in more deprived areas will have longer lengths of say. To do this kind of work requires data from the hospital on patient admission and length of stay linked to the community characteristics used to derive the deprivation score. There are multiple skills necessary to assemble the data before analyses even begin:
- Mining the electronic medical record to form the sample
- Downloading data from the Census (or other ecological data source) to create the deprivation index
- Linking the patient-level data to the community-level data (may entail geocoding)
The modern-day epidemiologist needs to be able to do all of these steps to create the analytic data set. Training in pathophysiology, statistics, and epidemiology alone would not necessarily provide the knowledge to perform these steps as it would require expertise in database systems, data scraping, data linkage, and geographic information systems. Regardless of whether the researcher carrying out the analyses is also the researcher assembling the data and/or is also the researcher overseeing this project, familiarity with the process to obtain these data is crucial to appreciate if selection bias and information bias may result from assumptions made along the way. In our hypothetical example, suppose the wrong patients were retrieved from the medical record, length of stay was incorrectly calculated, the wrong ecological unit was specified, or the geocoding was inaccurate and patients were linked to the wrong ecological unit. These errors could easily result in biases and lack of internal study validity that an epidemiologist who was distal to the data preparation process may not ever be aware of. The epidemiologist must maintain an intimate relationship with the data. And while this has always been true the fact that the data are now electronic (instead of hard copies) is an evolution of this field, much like the present-day physician no longer hand writes progress notes but rather documents them electronically. This evolution demands a revision in the training program to incorporate data science techniques. Thus, to answer the question, "Should all epidemiologists be data scientists?" for those of us who will engage in some aspect of research the answer is unequivocal YES!
Cite: Goldstein ND. Should all epidemiologists be data scientists?. May 2, 2019. DOI: 10.17918/goldsteinepi.